Code framework¶
While SPARTA is a fairly general framework, it does impose a particular workflow (i.e., order of operations) and a particular, although flexible, memory structure. The information on this page is not strictly speaking necessary in order to run SPARTA, but it will make it easier to understand how the individual modules work together.
Workflow¶
SPARTA goes through a simulation in a time-forward manner. After some small preliminary tasks, the main effort is in going through each snapshot of the simulation (or a subset selected by the user). The following flow chart shows this workflow.
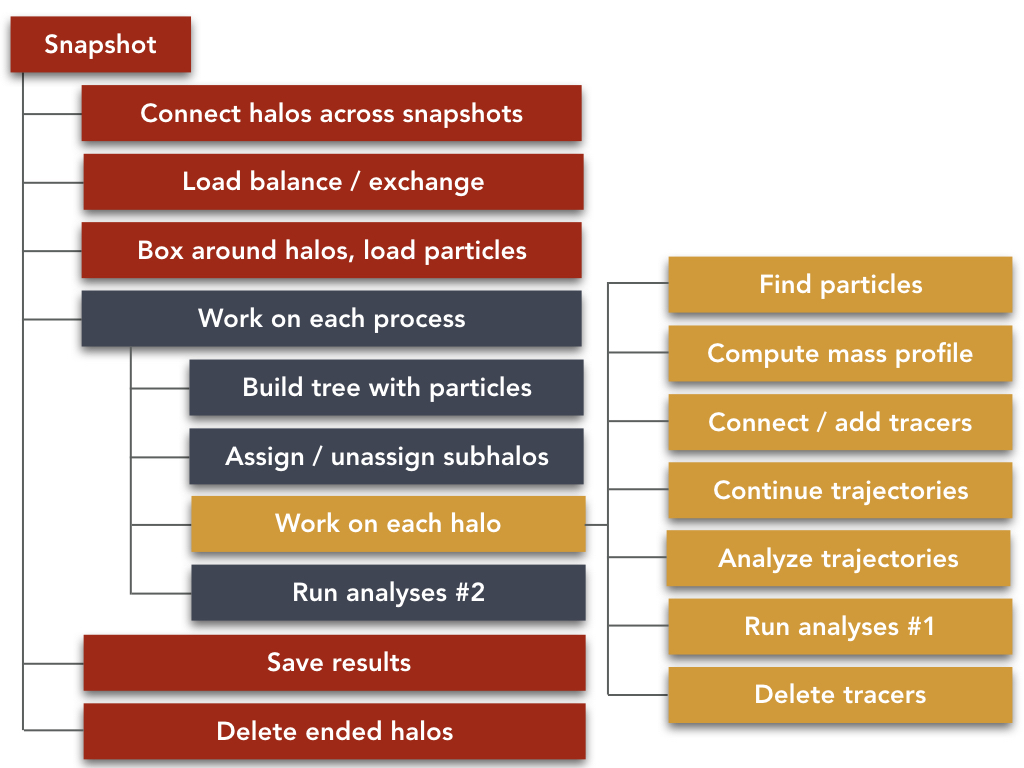
The tasks are split into a hierarchy with three levels, indicated by the different colors. They correspond to:
Red: Tasks that demand communication between processes. These tasks are often guided by the main process, which collects additional information from the workers. For example, all processes request the descendants of their halos from the main process, which then reads the halo catalog and distributes the information. Similarly, the output file is written solely by the main process.
Blue: Tasks that can be performed separately on each worker process, but that refer to the entire set of halos on that process. For example, we build one particle tree that is used to search for particles in all halos on that process. Similarly, the assignment of subhalos to their hosts demands knowledge about multiple halos at once.
Yellow: Tasks that refer to only one halo. Once the halos have been correctly initialized with their status and other information, the halo work does not make reference to other halos.
Note that results are saved to the HDF5 output file on a continuous basis. In particular, results are written per halo when a halo ends.
Domain decomposition¶
SPARTA is a fully MPI-parallelized code. The domain decomposition is performed over halos, meaning that each halo lives on one process. Whenever a new halo with no progenitor is found in the halo catalog, a new object is created and sent to the process that is responsible for its location in space. Subhalos are forced to live on the same process as their host. Two different domain decomposition schemes are available:
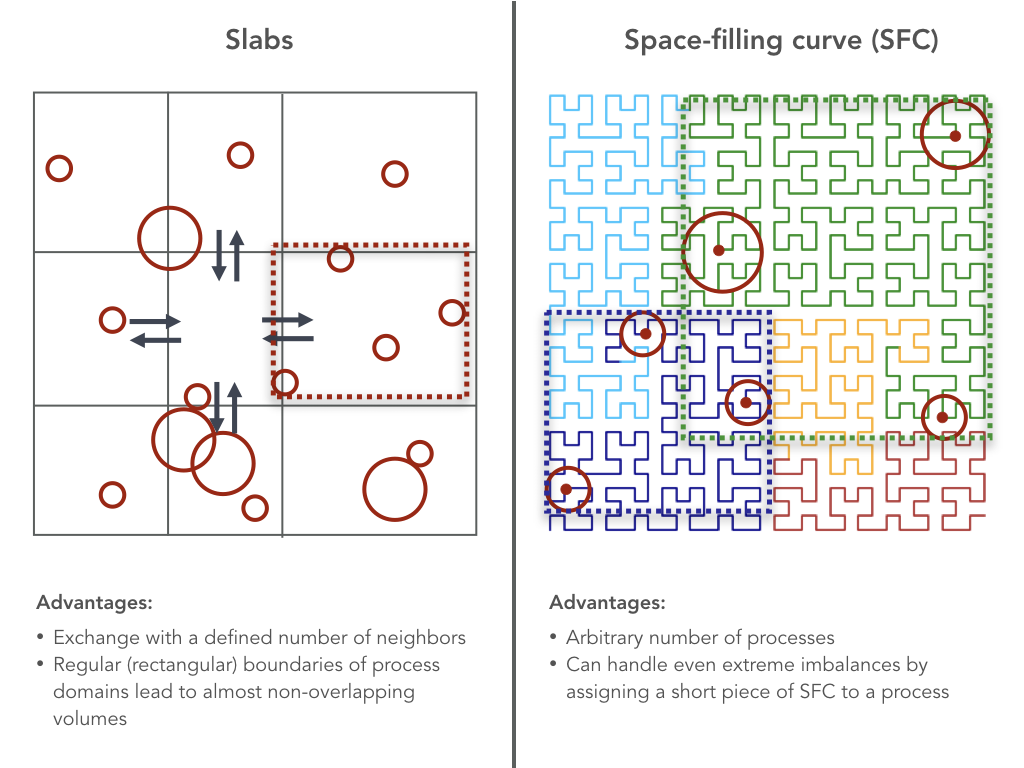
If the slab decomposition is chosen, the domain is divided into a series of slabs in each dimension, and the slab boundaries are slowly adjusted to balance out the work load. This scheme is fast and works well when the halos are distributed relatively evenly throughout the domain. The number of cores must be the multiple of three integers in the three dimensions.
The space-filling curve (SFC) decomposition uses a Peano-Hilbert curve to divide space. Halos centers are snapped to the nearest point in the curve as shown in the schematic above. The curve can then be divided into an arbitrary number of snippets. The advantage of this scheme is that the number of processes is arbitrary and that one process can obtain an arbitrarily small fraction of the SFC, for example, one very massive halo.
At each snapshot, each process computes the boundaries of the rectilinear, potentially periodic volume that contains all its halos, including a particular search radius around the halo centers. This radius depends on the tracers in each halo and various settings. All particles contained within the rectilinear volume are loaded from snapshot files, and a tree is constructed from their positions (we use the tree implementation of ROCKSTAR). For each halo, the particles within its search radius are found using a tree search.
Memory structure¶
The following chart shows the basic memory structure of SPARTA. The memory is organized on a per-halo basis because a halo has to always live on one process. When halos are exchanged between processes, all their dynamically allocated memory is also transferred. All large fields, such as the lists of tracer, result, and analysis objects, are dynamically allocated.
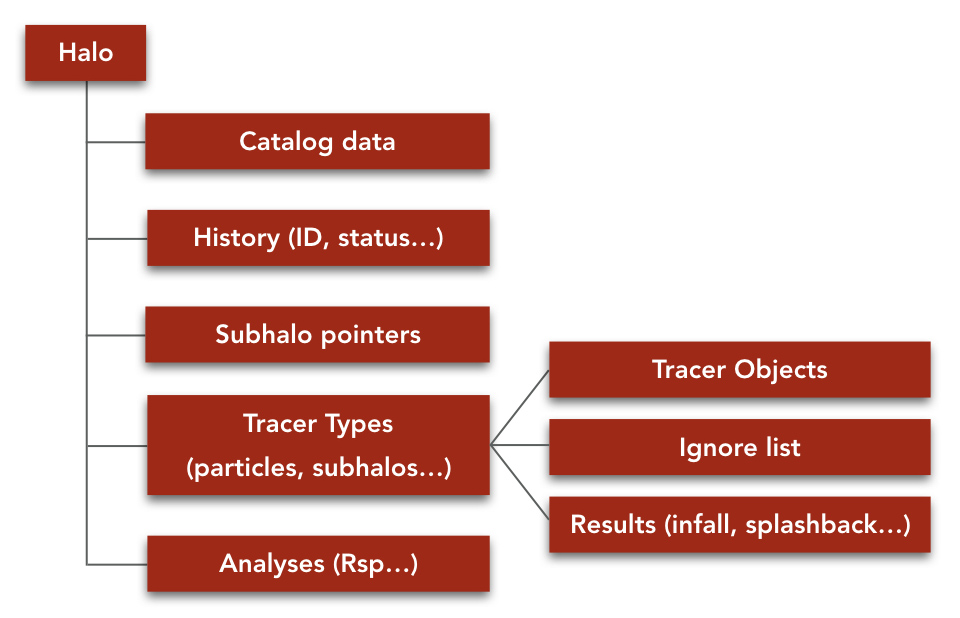
To avoid memory leaks, SPARTA uses an internal memory control system that detects even the smallest leaks and warns the user (though that should obviously never happen).
Restarting¶
When running on large simulations, SPARTA’s runtime can be significant, meaning that a crash at a late-time snapshot can be time-consuming to debug. For example, the memory consumption tends to increase with time as more and more halos are formed and as they grow, so that out-of-memory errors are likely to happen towards the end of the simulation. The code will then need to be run again with more memory per core.
To facilitate such changes and debugging, SPARTA offers full restarting capabilities. Binary restart files contain an image of the entire allocated memory on each process, as well as the current state of the output file. The user can decide how frequently restart files are written to disk. When restarting, SPARTA will continue from the most recent set of restart files as if nothing had happened.
During a restart, the basic configuration of the code cannot be changed, that is, the results and analyses that are enabled must stay the same. Similarly, the run-time configuration cannot be changed and the number of cores must remain the same. However, the but the code can be recompiled to fix bugs and/or turn on debug options, and the code can be run with a higher memory allocation.
Since restart files can become large, SPARTA automatically deletes old restart files when writing new ones.