What is SPARTA?¶
SPARTA is an analysis framework for particle-based simulations of structure formation. While many results can quickly be extracted using python scripts, there are some analyses that demand loading very large datasets and/or heavy computation. For example, any dynamical analysis of the trajectories of individual particles will fall under this category. SPARTA provides a general framework for such calculations.
Why SPARTA?¶
SPARTA essentially provides a flexible workflow for analyzing large amounts of data. If you implement a certain analysis within the SPARTA framework, the code takes care of the heavy lifting: reading particle data and halo catalogs, parallelizing the work over an arbitrary number of processes, load balancing, and saving the data into a (possibly very large) HDF5 file.
SPARTA works in a forward fashion, i.e. a SPARTA run begins at the first snapshot of a simulation where halos exist, and moves forward snapshot by snapshot.
Perhaps surprisingly, SPARTA is not is a halo finder: it relies on the results of other halo finders that need to be run before SPARTA can be run. SPARTA then combines the halo finder output with the original particle data, as shown in the schematic below.
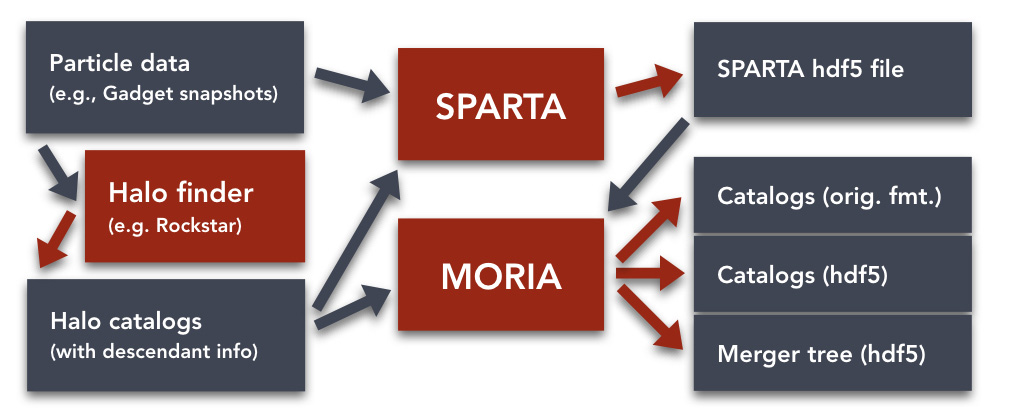
The outputs from SPARTA can take on a variety of forms, e.g., results that refer to individual particles or the results of computations that refer to individual halos. Regardless of their type, all results are stored in an HDF5 file. SPARTA includes a python package that reads these output files.
Due to the large variety of possible outputs, the results are not exactly in the form of a halo catalog, which is often the desired final data product. Moreover, SPARTA does not duplicate input from the original halo catalogs. To produce more convenient outputs, the MORIA tool combines SPARTA output with the original halo finder results and can output flexible, user-defined enhanced halo catalogs, either in the original halo finder format or as HDF5 files (see Creating halo catalogs with MORIA). The reason why MORIA is separate from SPARTA is that running SPARTA can take hours, whereas MORIA is typically quick. Moreover, the results from a single SPARTA run can be used in very diverse output catalogs chosen by the user.
Fundamental components¶
The architecture of SPARTA is based around a few fundamental concepts, the most important of which are listed here and described in more detail in the following pages:
Halos & Subhalos: SPARTA tracks all halos (host and sub) in a halo catalog through time, i.e. it holds one object per halo. Halos are the main object in Sparta, they contain basically all other information. A halo always lives on one process, but halos can be exchanged between processes.
Tracers: A tracer object represents a dynamical tracer such as a particle or subhalo. Each tracer has a trajectory with repect to the halo center, i.e., a time series of position in phase space relative to the halo. Tracers are created and destroyed according to certain rules that depend on the types of analysis to be performed on them. A tracer can exist in multiple halos at the same time.
Results & Analyses: In SPARTA, the term “result” refers to information that is specific to a tracer. For example, an infall result records information about a tracer when and where a tracer entered a halo, an orbit counter result contains information about the number of orbits the tracer has completed. In some cases, the term “event” would be more accurate, but for simplicity we will stick to “result”. Similar to results, analyses compute and record information, but they are specific to a halo rather than a tracer. Analyses can be executed while the halo is analyzed, after a snapshot’s work, or at the end of the run. They typically use tracer results to compute halo-wide quantities such as the splashback radius or density profiles.
As these categories are ubiquitous in the SPARTA code and its data products, each has long and short idenfitiers that are used interchangeably.
Type |
Long name |
Abbreviation |
|---|---|---|
Tracer |
|
|
Result |
|
|
Analysis |
|
|
Furthermore, the various incarnations of these categories also carry three-letter abbreviations
that are used throughout the code and its output, and that are interchangeable with the long names.
For example, a directory in the output file that contains information about splashback results
for particle tracers might be called tcr_ptl/res_sbk. However, we are getting ahead of
ourselves; the main components and their implementations are discussed in detail in the following
documentation pages.